[hide-toggle name="本文中使用的配置参考"]CPU : AMD R9-7940HX
GPU : NV RTX4060Laptop
MEM : 32G[/hide-toggle]
[hide-toggle name="本文中使用的配置参考"]CPU : AMD R9-7940HX
GPU : NV RTX4060Laptop
MEM : 32G[/hide-toggle]
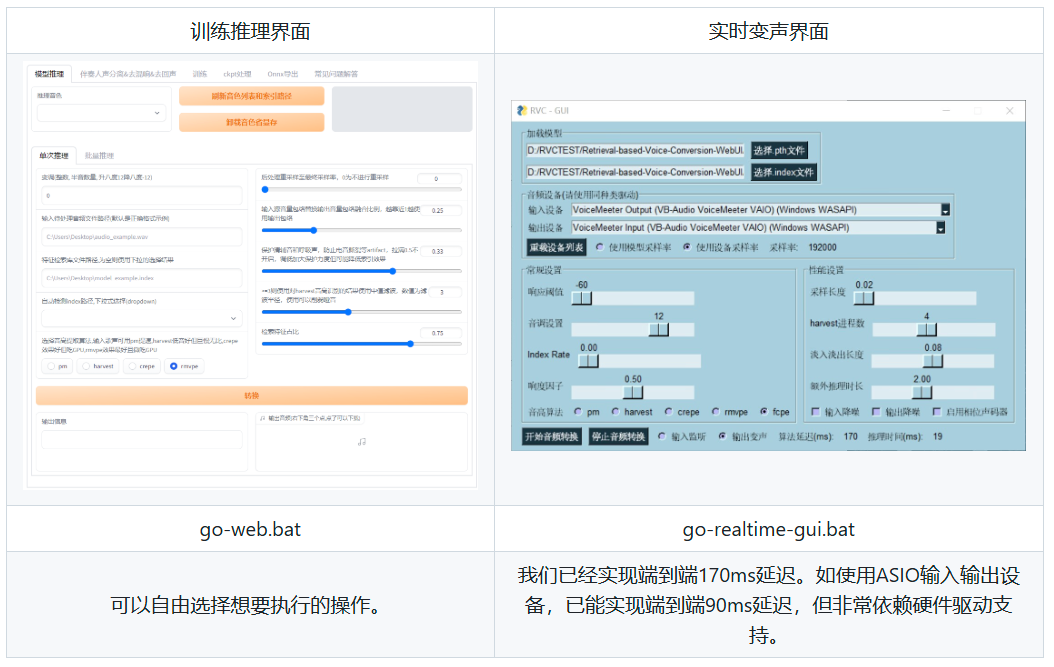
- 下载及使用RVC
项目地址:https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
下载对应的版本,此处不多赘述
解压文件至无中文路径中,打开go-web.bat,等待一会会弹出一个网页
- 准备声音训练数据集
准备5分钟以上的wav格式纯人声音频,如无则可通过RVC自带的人声分离
准备好待处理的音频,并打开刚刚的网页,选择伴奏人声分离&去混响&去人声,分离模型可自行根据说明进行选择,输出格式依然选择wav
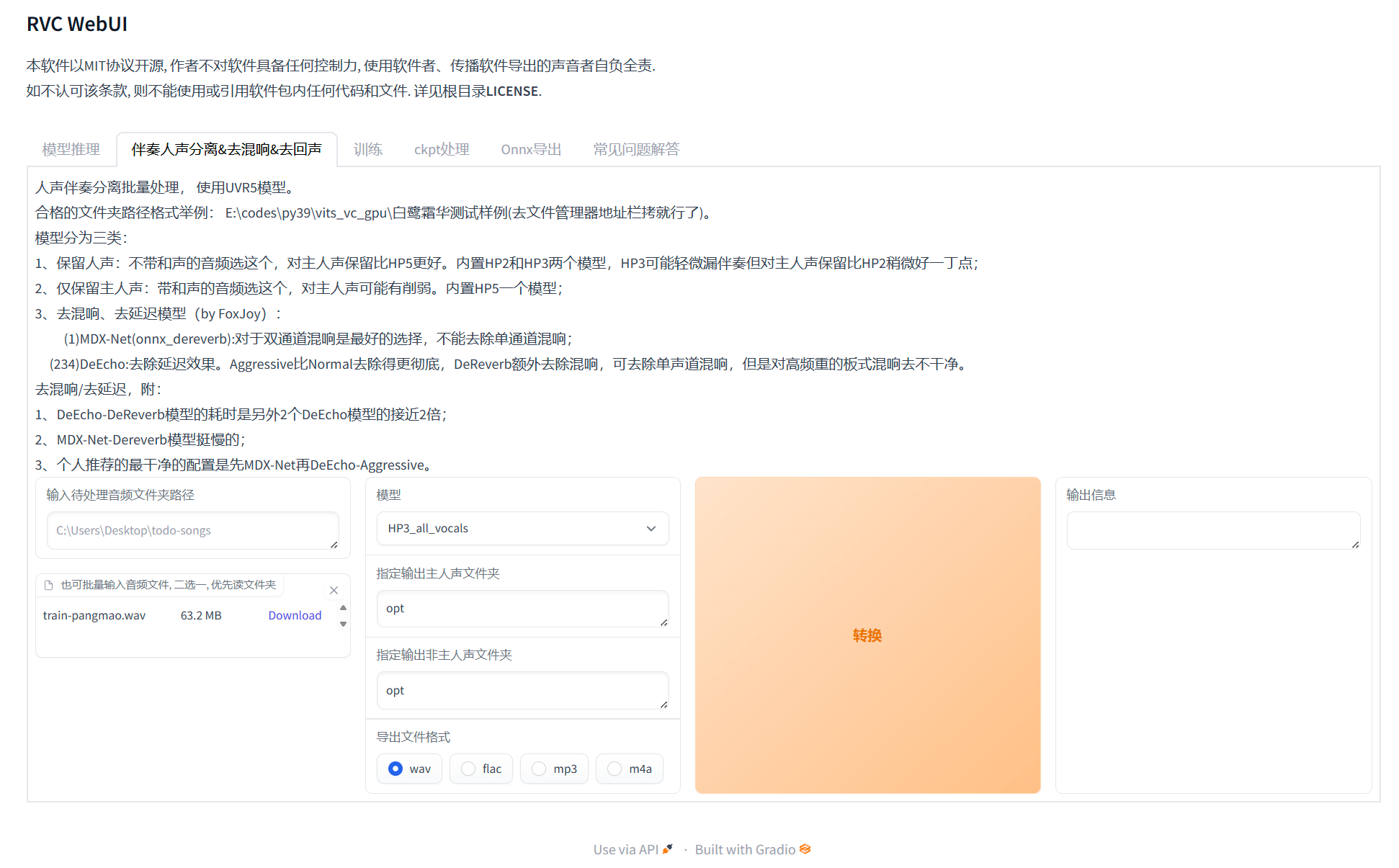 如图点击转换即可处理。进入rvc/opt即可看到输出的音频文件,复制文件路径
如图点击转换即可处理。进入rvc/opt即可看到输出的音频文件,复制文件路径 - 进行训练
在webui中选择“训练”
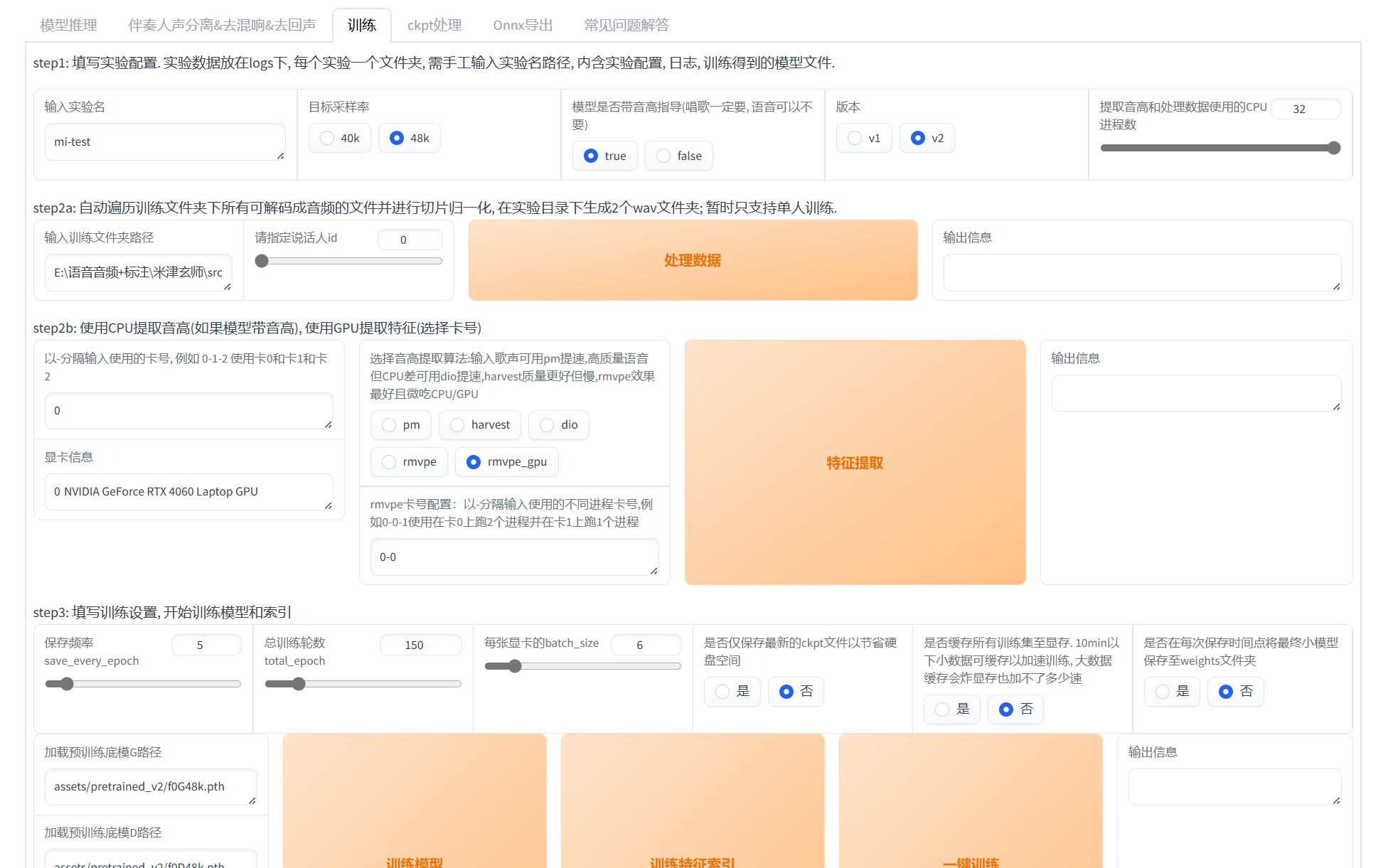 目标采样率建议选择48k,输入训练文件夹路径粘贴刚复制的数据集所在文件夹路径,总训练轮数视情况而定,这里选择了30轮保存,总150轮,其他设置视机器配置而定,4060laptop训练6分钟的数据,耗时约6小时,点击“一键训练”即可开始
目标采样率建议选择48k,输入训练文件夹路径粘贴刚复制的数据集所在文件夹路径,总训练轮数视情况而定,这里选择了30轮保存,总150轮,其他设置视机器配置而定,4060laptop训练6分钟的数据,耗时约6小时,点击“一键训练”即可开始 - 模型推理
训练完成后的模型会保存在rvc/assets/weights下,底模文件“在rvc/logs/"实验名"/*.index”
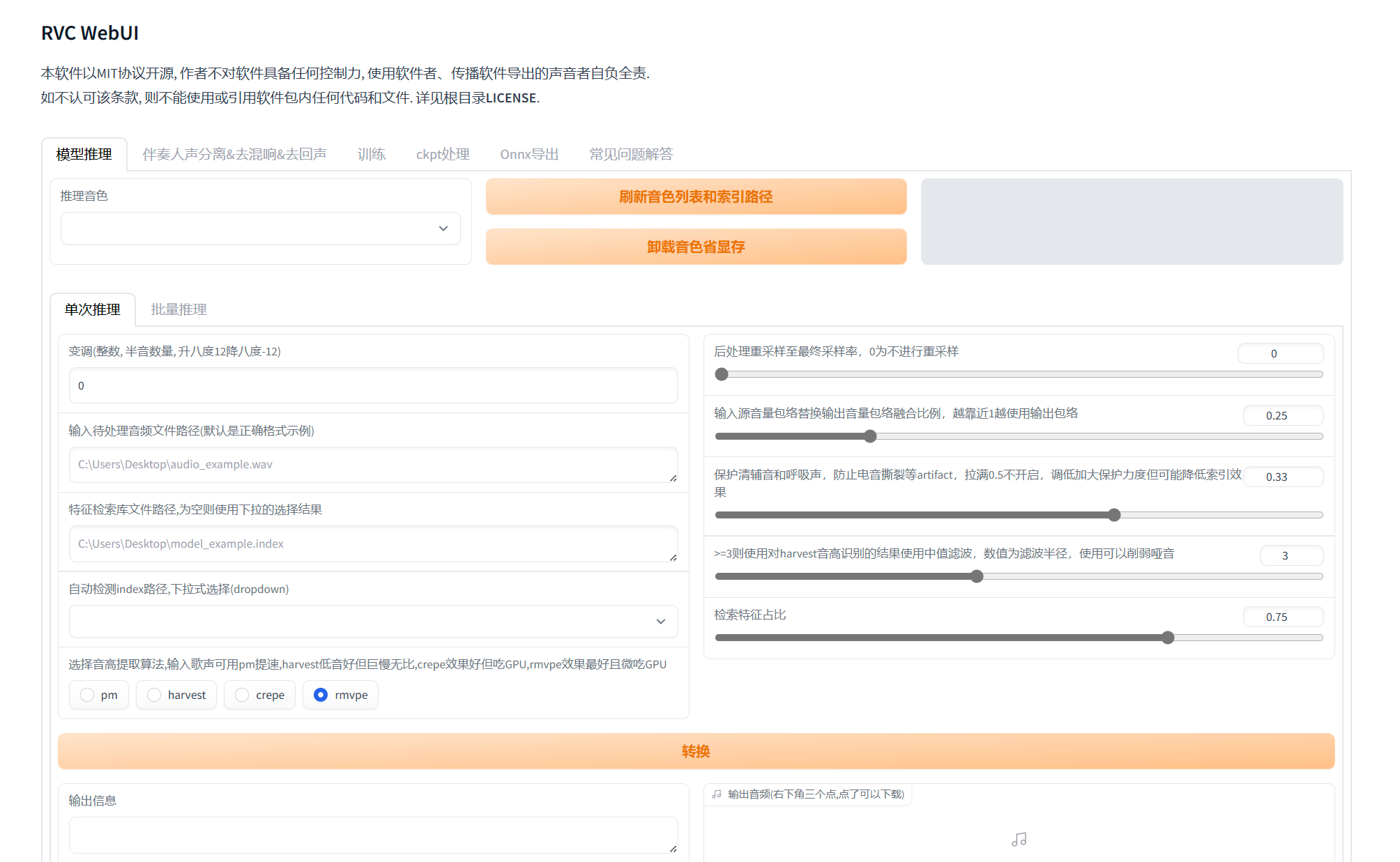
在webui中选择推理,刷新音色列表及索引路径,选择训练出来的模型,接着输入想要变声的音频文件路径
例:
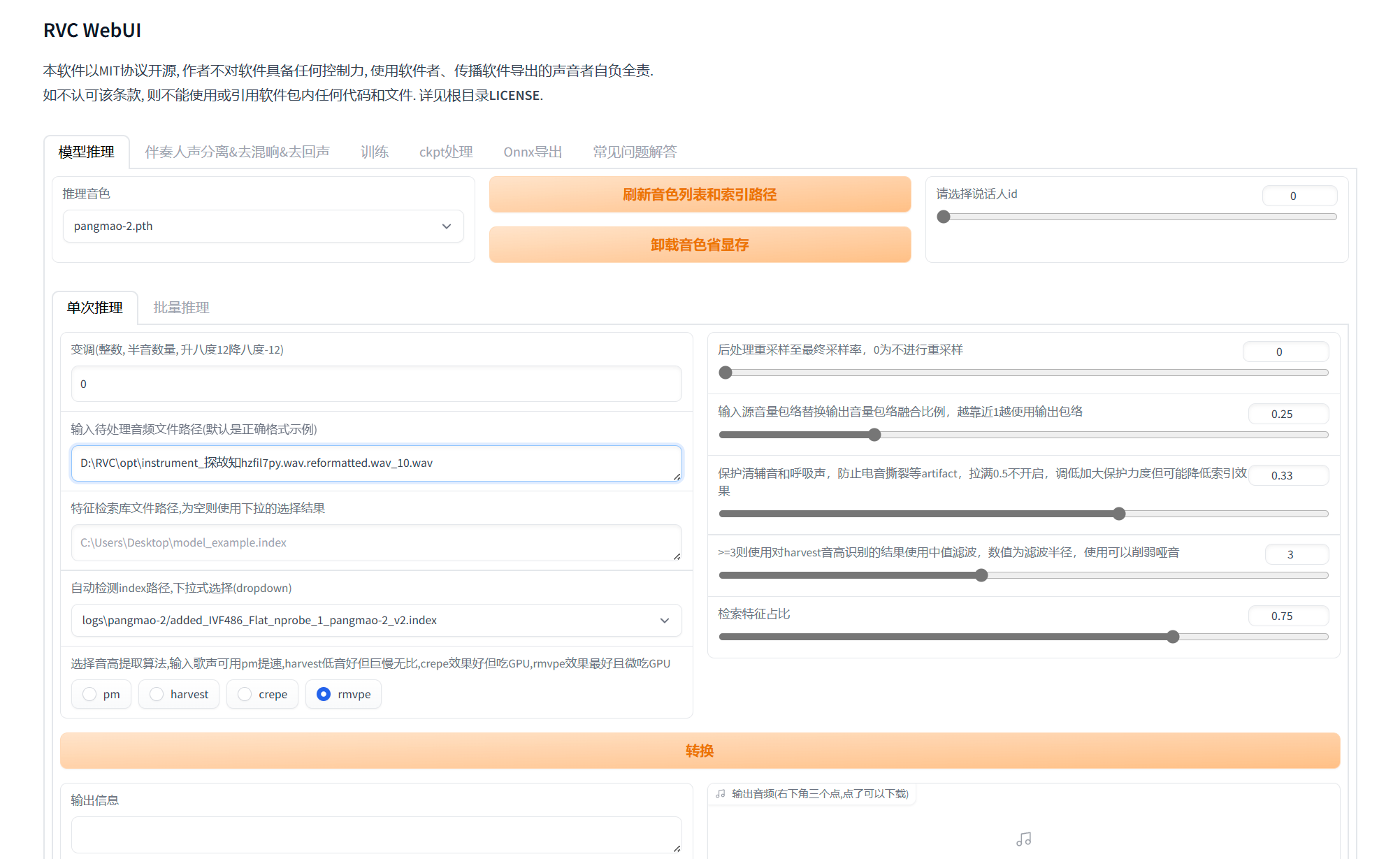 点击开始转换,很快就可以得到输出的结果
点击开始转换,很快就可以得到输出的结果 - 实时变声 训练出来的模型可用于RVC实时变声,这里不多进行赘述,网上有很多相关教程,需下载虚拟声卡如VoiceMeeter,使用rvc目录下的go-realtime-gui.bat